A/B Testing · Field Guide · 2026
Shopify A/B Testing: The Complete 2026 Guide
Shopify finally shipped native A/B testing in 2026, but it will not tell you whether your result is real. This is the honest version: how to run an A/B test on your store, even on low traffic, and judge every change on the money it actually makes.

You ship a change to your product page on a Tuesday. New hero image, a tidier buy button, a line about free returns. By Friday, sales are up. You feel it: the thing worked. You start telling people the new page is better.
Then the doubt creeps in. Was it the change, or was it just a good week? Maybe a creator mentioned you. Maybe payday landed. Maybe last week was unusually slow and this week is just normal. You changed one thing and a hundred other things changed around it, and now you genuinely cannot tell which one moved the number. That is the whole problem. Most store changes get judged by a feeling and a before/after glance, and a before/after glance cannot separate your edit from the weather.
An A/B test (also called a split test) fixes exactly this. It shows the old version and the new version to real shoppers at the same time, splits them at random, and measures which one earns more money per visitor. Same week, same ads, same season for both. Whatever is left over is your change, and nothing else. It is the closest thing a Shopify store has to proof.
This guide is the honest version of how to do that. Not the enterprise version that quietly assumes you have a million visitors a month, and not the hype version that promises every test wins. We will cover what Shopify's new native testing can and cannot do, how much traffic you actually need (the real number is harder than most guides admit), how to test when traffic is thin, what to test first, and the statistical traps that make a test lie to you. You already paid for the traffic. The point of testing is to stop handing it back.
The short answer: test the change against itself, judge it on revenue per visitor, set your finish line before you start, and treat "not enough data" as a reason to test differently, not a reason to quit.
What is A/B testing on Shopify, and what is it not for?
An A/B test splits your live traffic into two random groups at the same moment, shows one group your current page and the other a changed version, keeps each shopper on their assigned version for the whole visit, and measures which one earns more money per visitor. The random split is the whole point. Because the only systematic difference between the two groups is the change you made, any gap in revenue can be credited to that change and nothing else. Same season, same ads, same sale, same weather. That is what separates a test from a hunch. You are not comparing your store to last month or to a competitor. You are comparing your store to a parallel copy of itself, running side by side, where the one thing you altered is the one thing under examination.
That word, random, is doing the heavy lifting. Send shoppers to version A or version B by a coin flip and the two groups end up alike in every way that matters: device mix, traffic source, intent, time of day. So when revenue per visitor comes out higher on B, you have a cause, not a coincidence. This is the line between cause and effect on one side and correlation on the other.
It helps to be clear about what an A/B test is not, because plenty of tools get filed in the same drawer and answer a completely different question. Heatmaps, session recordings, and analytics (Hotjar, Microsoft Clarity, GA4) tell you what shoppers do: where they tap, where they stall, where they leave. That is observation. An A/B test is the only tool that tells you whether a change actually caused more revenue. One shows you the symptom; the other lets you act and confirm the cure paid off.
Analytics show you what is happening. An A/B test is the only thing that proves a change made you money instead of just looking like it did.
A test is also not a before-and-after. Running your old page in February and the new one in March feels like a comparison, but it is confounded by everything else that moved in between: a sale, a new ad campaign, a payday, a cold snap. You cannot tell the change from the calendar. A test is not a guarantee either, and it is not a statistics class. You set up the two versions, let real shoppers decide, and read the result honestly.
Two terms you will see throughout this guide. The control is your current page, the version already running (sometimes called the champion). The variant is the changed version you are putting up against it (the challenger). Keep it to one change at a time so you know exactly what caused the result. The alternative, multivariate testing, varies several elements at once to find the best combination, but it needs far more traffic than a clean A/B test and is the wrong tool for almost every Shopify store. Start with one clear hypothesis, one change, one verdict.
Here is the honest part most tools skip, and it is worth knowing before you start so the math feels like planning rather than failure. Most changes you test will not win. In areas you have not optimized before, the rough split is about a third of tests win, a third come out flat, and a third actually lose. In mature, already-tuned areas, the win rate drops to roughly 10% to 20% (Ron Kohavi, Trustworthy Online Controlled Experiments, 2020). That is not a reason to avoid testing. It is the reason to test at all. The whole job is to find the changes that genuinely help and to keep yourself from shipping the ones that quietly cost you, which you could never tell apart by eye. The verdict StorePilot reports is never a single number. It is a range with a confidence word attached, and it walks from exploratory to likely to strong only as the evidence earns it.
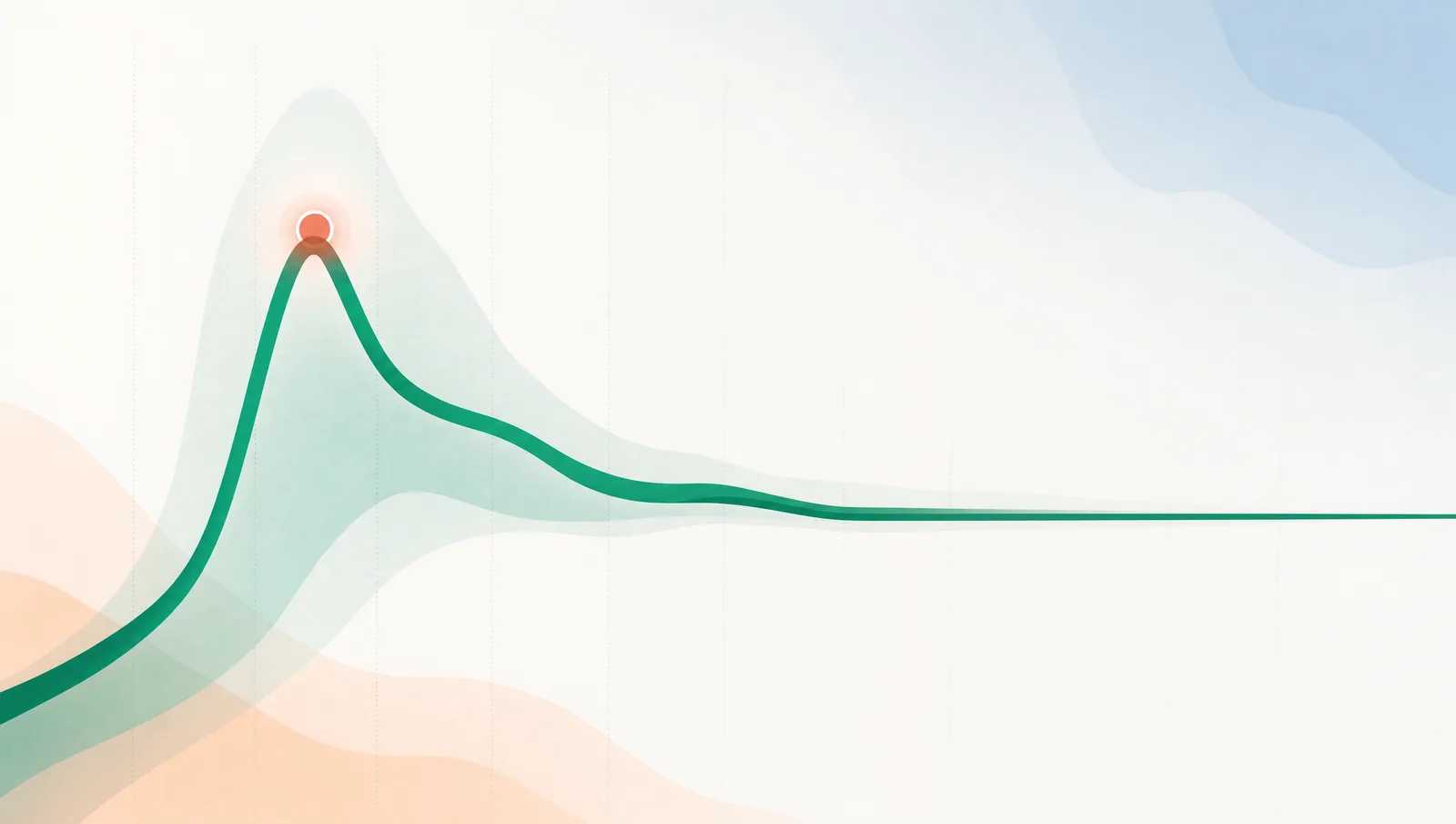
The figure below shows what an honest verdict looks like as the data comes in: two revenue-per-visitor curves whose uncertainty bands narrow and pull apart over the run, resolving into a range rather than a false point estimate.
Grey is your current page, green is the variant. The width of each curve is the uncertainty. An honest test resolves to a range with a confidence word attached, never a single number and never a fake 100% win.
That mindset, observe then act then confirm on revenue, runs through the broader CRO playbook. And if you are wondering whether you even have something worth testing, the data says you almost certainly do: most stores have at least one conversion leak sitting in plain sight.
Does Shopify have built-in A/B testing? (Rollouts in 2026)
Yes. As of January 2026, with the Winter '26 RenAIssance Edition, Shopify ships native A/B testing called Rollouts. It splits live traffic between theme versions inside the admin, on the server, with no extra apps and no script bolted onto your storefront. That is genuinely useful, and it is also where most of the "do I even need an app?" question gets answered. Rollouts is plumbing, not a brain. It pours your traffic into two versions and shows you what happened. It does not tell you whether what happened is real, whether the version that "won" actually made more money per visitor, or what you should have tested in the first place. So the honest answer for most merchants is: Shopify now gives you the splitter for free, and you still need something to decide what to split and whether it truly won.
Rollouts lives in the admin under Markets and works server-side. You pick a theme version, set the share of traffic that sees it, schedule the release, and Shopify can roll it back automatically if things go wrong. Because the split happens on Shopify's servers before the page is sent, there is no client-side script swapping content after load. That matters more than it sounds: no flicker, no flash of the old version, and no drag on your Core Web Vitals. The variant is there at first paint, the way a clean test should be.
There is a catch worth knowing before you get excited. The real traffic-splitting and experiment analytics require the Grow plan or higher. On Basic and the standard plan, Rollouts gives you scheduled deploys and automatic rollbacks, not A/B testing. A lot of merchants discover that gate only after they go looking for the split-test toggle, so check your plan first. (Verify the exact plan line against Shopify's own help docs at the time you read this; the gate has moved before.)
What can Rollouts test? Whole-theme swaps, section layouts, navigation and menus, promo banners, and the way your homepage and collection pages are organized. As of mid-2026, per agency testing, that is the working list, and it is likely to grow. We keep a full breakdown of what Rollouts can and cannot test, and how it stacks up against Intelligems, Shoplift and Convert, in Shopify just shipped native A/B testing. Now what?
What it cannot test is the more important list:
- Checkout, which is shared across theme versions and stays locked down.
- Pricing and discounts.
- App embeds and third-party content.
- Liquid template changes and global theme settings.
- Audience segmentation, like new visitors versus returning ones.
- Custom conversion goals. It also tests your published theme only.
Then there is the honest gap, the part that decides whether Rollouts is enough on its own. It does not compute statistical significance. It does not declare a winner. It does not think in revenue per visitor, the metric that actually tracks whether you made more money rather than just more orders. And it has no answer for a low-traffic store beyond "run it longer," which for most Shopify merchants means a test that outlives the season it was meant to help. Rollouts splits your traffic and shows you the analytics. Reading those analytics honestly, and knowing when a lead is real versus random noise, is still on you.
One more thing to clear up, because the search results still send people the wrong way: Google Optimize is gone. Google sunset it on September 30, 2023, with no replacement. If a guide or a forum thread tells you to wire Google Optimize into your Shopify store, it is years out of date. Native Rollouts is the closest free successor, and it is built into the platform.
Shopify gives you the pipes. The brain, what to test, how to build the variant, and whether it actually made more money per visitor, is the part you add.
So treat Rollouts as the safe, free splitter it is. It is a real upgrade over the old days of hacking your theme files and hoping. But splitting traffic is the easy half of an A/B test. The hard half, deciding what is worth testing, building the variant, and judging the result on revenue per visitor without fooling yourself, is the work that earns the lift. That is the layer you bolt on top, whether that is an app, a careful method, or a tool that runs the testing loop for you.
What does statistical significance actually mean for a Shopify test?
It is the discipline of ruling out luck before you believe a result. When version B comes out ahead in a test, there are only two explanations: B is genuinely better, or B got a lucky draw in the random split. Statistical significance is how you tell those two apart. It puts a number on how easily plain chance could have produced the gap you are looking at. If chance could explain it, you do not have a finding yet. You have a coin that happened to land your way. The whole point is to stop you from shipping a change that did nothing, then crediting yourself for a lift that was never there.
Every test has noise in it. Two groups of shoppers, even shown the exact same page, will never convert at precisely the same rate. One group buys a bit more this week for reasons that have nothing to do with your change: payday, weather, a viral TikTok, who happened to walk in the door. So the real question is never "did B beat A?" It is "did B beat A by more than the normal week-to-week wobble?" Significance is the line between a gap big enough to take seriously and a gap that is just the wobble.
The tool that draws that line is the p-value. Put plainly: if the two versions were truly identical, how often would random chance alone produce a gap this big or bigger? A small p-value means "rarely," so you start to believe the difference is real. A p-value of 0.03 means a gap this size would turn up only 3% of the time if the versions were actually the same. That is uncommon enough to act on. A p-value of 0.40 means the gap shows up 40% of the time by pure luck, which tells you nothing.
Here is where almost everyone, including people who should know better, reads it backwards.
So 95% confidence does not mean "95% chance B is the winner." It means you set your tolerance for being fooled at 5%. That 5% (called alpha) is the long-run false-positive rate of the procedure: if you ran a hundred tests on changes that genuinely did nothing, about five of them would still cross the line and look like winners by chance alone. The 95% describes the rulebook you are using, not the odds on this one result. It is a quality standard for the method, the way "inspected to 99% accuracy" describes the factory, not the single part in your hand.
A p-value tells you how surprised to be if nothing was going on. It does not tell you the odds that something was. Treat it as a smoke alarm, not a verdict.
Once you stop reading the p-value as a win probability, a better habit takes over: report the range, not the single number. Instead of "B lifted revenue per visitor 8%," report the confidence interval: "+2% to +14%, most likely +8%." That range is the honest answer, because a test never hands you one true number. It hands you a best guess with a margin of error around it.
The interval also catches the mistake that costs merchants the most: calling a coin flip a win. A reading of "−3% to +11%" looks positive at a glance. It is not. Zero is inside the range, which means doing nothing is still a live possibility, so you ship at your peril. A clean win is an interval that sits entirely above 0. Anything straddling it is a "keep running" or a "let it go," never a "publish it."
This is also why StorePilot does not hand you a raw p-value and walk away. A p-value is the single most misread number in this whole field, and a merchant who reads it as "97% chance I win" will make a confident, wrong call. So we translate the math into calibrated words: exploratory, likely, strong. "Exploratory" means an early signal worth a second look. "Likely" means proceed, but keep watching. "Strong" means ship it. Those words map to real thresholds on the interval and the evidence behind it, and "strong" has to be earned from a track record of holding up, never asserted from one good week. The number is still there underneath for anyone who wants it. The word is what keeps an honest result from being read dishonestly. For the wider picture on baselines and how Shopify stores actually convert, see the numbers behind Shopify conversion.
How much traffic do you need, and how long will a Shopify test take?
Most small Shopify stores cannot reach textbook significance on a realistic lift inside a sensible window. That is math, not opinion, and it is better to know it before you start than to wait six months for an answer that never arrives. A test needs a certain amount of traffic to tell a real difference from random noise. The smaller the difference you want to catch, the more visitors it takes, and the relationship is steeper than almost anyone expects.
Four things drive how much traffic a test needs: your baseline conversion rate, the minimum detectable effect (MDE), your confidence level, and statistical power. The last two are usually fixed at sensible defaults (95% confidence, 80% power). So on a real Shopify store, two knobs do almost all the work: how often people currently convert, and how small a change you are trying to detect.
The MDE is where the trap lives. There is a law worth tattooing on the inside of your eyelids: the traffic you need scales with one over the MDE squared. Halve the lift you want to detect and you roughly quadruple the visitors required. Chasing a small win is exponentially more expensive than chasing a big one. A button-color tweak that might move conversions 3% can need an order of magnitude more traffic than a full product-page redesign you'd expect to move them 20%.
Halve the lift you want to catch, and you quadruple the traffic you need. Small wins are not cheaper to prove. They are far more expensive.
You do not need a calculator to feel the scale of this. A rough back-of-envelope rule gets you close: visitors per variant ≈ 16 / (p × r²), where p is your current conversion rate as a decimal and r is the relative lift you want to detect, also as a decimal. For a store converting at 2% chasing a +10% lift, that is 16 / (0.02 × 0.10²), which lands around 80,000 visitors per variant. Across the 1–3% conversion rates and 5–20% lifts most Shopify stores live in, this napkin rule stays within about 6% of the exact two-proportion formula. Close enough to plan with. And if you are not sure what a normal baseline even looks like for your vertical, the 2026 Shopify conversion benchmarks show where stores like yours actually sit.
Here is what the exact math says you need, per variant, to detect a given lift at 95% confidence and 80% power. Remember these are per variant, so double them for the total test.
| Your current conversion rate | To detect +5% | To detect +10% | To detect +20% |
|---|---|---|---|
| 1% | ~637,000 | ~163,000 | ~42,700 |
| 2% | ~315,000 | ~80,700 | ~21,100 |
| 3% | ~208,000 | ~53,200 | ~13,900 |
Two-proportion test, 50/50 split, two-sided. Order-of-magnitude figures: real needs run higher once you account for novelty, weekly cycles, and that revenue per visitor is noisier than conversion rate. Double each number to get the total traffic the test needs.
Read the middle of that table and the problem comes into focus. A store converting at 3% needs roughly 53,000 visitors per variant (about 106,000 total) to reliably catch a +10% lift. Push the target down to a +5% lift and the requirement balloons to around 208,000 per variant. Same store, half the ambition, four times the traffic. That is the squared law doing its quiet, brutal work.
Now turn visitors into time, because time is what you actually feel. Take a real small store: 5,000 sessions a month, converting at 2%, hoping to detect a +10% lift. The math wants roughly 161,000 sessions in total. At 5,000 a month, that is about 2.7 years. The test outlives the season, the product line, and sometimes the store. A 5% target on that same store is, for practical purposes, never.
It is not only the smallest stores. A store doing 20,000 sessions a month, converting at 2%, needs about five months to settle a +10% test, and somewhere in the 1.5-to-2-year range for a +5% one. The same store can resolve a +20% test in roughly nine weeks, because a bigger target needs far less data. The difference between those windows is entirely the size of the change you chose to test.
The figure below shows the same idea as fill-up bars: three stores, the same +10% target lift, and how long each takes to reach the sample it needs.
The doable window for a classic A/B test is roughly 2 to 6 weeks. Below that line, you change method instead of waiting, which is the next section.
A useful filter: a healthy test runs about two to six weeks. Long enough to cover full business cycles, short enough that the world hasn't changed underneath you. Look back at the grid and almost every row for a small store blows past that window. That is the real reason low-traffic stores struggle with classic A/B testing, and it is why the answer is to change what you test and how you measure it, not just to wait longer. We get into that next.
Two honesty notes on the numbers above. They are order-of-magnitude illustrations, built on a clean two-proportion calculation with a 50/50 split and no peeking. Your real requirement is usually higher, because novelty effects, weekly seasonality, and the fact that revenue per visitor is noisier than a simple conversion rate all add variance. Treat these as the floor, not the ceiling. If you want to sanity-check the conversion rate you're starting from, our Shopify CRO statistics piece has the real baselines, because the 2% you assume and the 1.4% you actually run change every number on this page.
Can you run A/B tests on a low-traffic Shopify store?
Yes, but you change what you test and how you measure it instead of waiting forever. The standard advice ("wait for 95% confidence") quietly assumes enterprise traffic. Most Shopify stores are nowhere near it, so the textbook A/B test (split, wait, declare) simply never finishes on a 3,000-visitor-a-month store. The honest move is not to give up. It is to swap the method. You test bolder changes, you measure them with a holdback instead of a clean 50/50, and you lean on what already worked across thousands of other stores. The trade is real: you cap your confidence at "likely" instead of "strong," and a human approves before anything sticks. But "likely, and shipped" beats "strong, and never." The cruelest thing a testing tool can tell a small merchant is "not enough data yet," forever. That sentence is the top reason small stores quit A/B tools, and it is usually a method problem, not a you problem.
Start by finding your real number. Not site-wide sessions: the monthly sessions on the specific page or template you want to test. A product page that gets 1,800 visits a month plays by different rules than your homepage. Find that number, then read across.
Here is the decision rule, by traffic tier.
| Traffic on that page or template | Honest method | Confidence you can earn |
|---|---|---|
| 50,000+ / month | Concurrent A/B test, 95%, run to full power | Up to "strong" |
| 10,000 to 50,000 / month | A/B for bold changes only; apply-and-measure for smaller ones | "likely" toward "strong" |
| 2,000 to 10,000 / month | Apply-and-measure with a holdback; pool up to the template level | "likely" at best |
| Under ~2,000 / month | Apply-and-measure on changes backed by strong cross-store priors; ship low-risk fixes and monitor; painted-door for big bets | "exploratory," sometimes "likely" |
The pattern is simple. More traffic buys more rigor. Less traffic means you test bigger swings and accept softer verdicts. Below roughly 2,000 sessions on the page, a classic A/B test is mostly theater, so you shift to shipping well-evidenced fixes and measuring them honestly after the fact.
There are five levers, and the order matters.
1. Test bigger. This is the lever everyone skips, and it is the most powerful one. The traffic a test needs scales with one over the square of the effect you want to detect, so a change you expect to move revenue per visitor by 20% needs roughly sixteen times less traffic to prove than a 5% tweak. Button-color tests are a luxury for stores with traffic to burn. On a small store, only test changes you genuinely expect to move RPV by 15% or more. Skip the shade of green. Test a sticky Add to Cart bar on mobile, a free-shipping threshold bar, visible reviews versus none, or a bolder product-page layout. Big, structural, reversible changes are the low-traffic merchant's whole game.
2. Apply-and-measure with a holdback. This is the workhorse. Instead of a 50/50 split that starves both versions, you ship the new version to 80 to 90% of visitors and keep 10 to 20% on the old one as a living control. Then you compare the treated group against that holdback, and against a matched period before the change, for a second read. The honest label on this method is "measured, not fully controlled." It is weaker than a clean 50/50, its confidence caps at "likely," and a person signs off before it becomes permanent. Never autopilot. One technique makes this far more powerful: CUPED, which uses your store's own recent history to strip out noise. When the pre-period predicts the outcome well, CUPED cuts the traffic you need by roughly 30 to 50%. It is not exotic. Microsoft built it in 2013, and Netflix, Booking, and Airbnb all run it. Cart-level holdbacks work the same way.
3. Clean before/after with matched controls. This is the method to use carefully, because a naive before/after is the confounded trap from earlier in this guide. Done with discipline, it earns an "exploratory" read. The technique has a name (interrupted time series) and a checklist.
- Match day-of-week and season. Compare the same Tuesdays, not a Tuesday against a Saturday.
- Exclude any window touched by a sale, an ad-spend change, or a PR spike.
- Use an unchanged comparison page as a baseline, so a market-wide swing shows up in both.
- Require a stable post-period of at least 14 days, and confirm week two roughly matches week one.
- Always read it on revenue per visitor. A sale inflates conversion rate while quietly cutting order value. RPV catches what CVR hides.
This is the weakest of the five. Treat its results as a signal to investigate, never as proof.
4. Pool traffic up a level. One product page may get 1,800 visits a month. The product-page template, across every product, might get 70,000. So test the template, not the single product, and you can have forty times the data overnight. There is one catch worth understanding. When the thing you change is shared across many pages, the unit you measure has to be the page or a time window, not the individual visitor, or the groups bleed into each other and the math breaks. And if the change helps your apparel and hurts your electronics, that split is a finding, not noise. It tells you where the fix belongs.
5. Lean on priors and cross-store evidence. Some fixes are so well-evidenced, and so cheap to reverse, that spending three months "proving" them on your own thin traffic is the actual mistake. Add visible reviews. Show a shipping line near the buy button. You ship those and monitor, rather than gatekeep them behind a test that will never reach significance. The discipline here is strict: a prior is calibration, never a forecast dressed up as your own result. It is always shown as secondary to your real data, and it widens your confidence range rather than tightening it. Cross-store evidence tells you what tends to work. Only your store tells you what did.
"Likely, and shipped this month" beats "strong, and proven in two years." On a small store, the second option is just a slower way of doing nothing.
There is one more tool for the boldest bets: the painted-door test, done honestly. If you are weighing a feature you have not built yet (a subscription option, a bundle builder, a new product line), you can measure real demand before committing. You surface the option, count how many shoppers reach for it, then tell the truth: "Coming soon, want us to notify you?" You never take money for something that does not exist, never fake a broken checkout, never manufacture scarcity. This is the exact opposite of a fake countdown timer. Same surface, opposite ethics. One measures genuine intent and respects the shopper; the other manufactures panic and erodes trust. It matters, because building the wrong thing is expensive. CB Insights found that roughly 35% of startups fail because there was no market need for what they made. A painted-door test is how you check for the door before you build the room.
None of this is a workaround that pretends low traffic does not matter. It is the opposite: it is being honest that it does, and changing the game so you can still learn and earn while you grow. You test the big things, you measure with a holdback, you borrow proven priors with the volume turned down, and you let a person make the final call. The verdict says "likely" instead of "strong," and that word is doing real work. It means proceed, watch, and be ready to reverse. For a store paying for every visitor, that is a far better position than waiting two years for a certainty that never comes.
Why measure revenue per visitor instead of conversion rate?
Revenue per visitor (RPV = total revenue / sessions) is the metric that pays your bills, because it counts two things at once: whether people buy and how much they spend. Conversion rate only counts the first. That gap is where merchants get fooled. A change can push your conversion rate up, show a confident green "+9%," and quietly leave you with less money in the bank at the end of the month. RPV is the scoreboard that can't be gamed this way, because it is tied directly to the number you actually care about. The version that wins on conversion rate is not always the version that wins on revenue. Judge on RPV and the trap closes.
Here is the trap, with real numbers. Say you run a "10% off, next 10 minutes" banner against your normal product page. The control gets 1,000 sessions and 30 orders: a 3.0% conversion rate, an $80 average order value, an RPV of $2.40. The variant with the banner gets 1,000 sessions and 36 orders: a 3.6% conversion rate. That's a 20% lift in conversions. The dashboard lights up. But the banner pulled people toward smaller, discount-driven baskets, so average order value drops to $62, and the variant's RPV lands at $2.23. Conversions went up. Money went down. A tool that watches conversion rate calls this a winner and tells you to ship it. A tool that watches RPV calls it a loser and saves you from yourself.
A conversion-rate win that loses on revenue per visitor is not a win. It is a discount you talked yourself into.
This happens for a structural reason. Discounts, urgency mechanics, and free-gift offers nearly all trade margin and order value for a few extra checkouts. Conversion rate is a proximate metric: it sits near the start of the money, not at the end of it. Revenue is the real outcome, what experimenters call the overall evaluation criterion, the one number a test is allowed to declare a winner on. You can read more on the discount math in our guide to AOV and the discount trap.
RPV is the honest metric, but it is also the harder one statistically, and you should know that going in. Conversion rate is a clean yes/no per session. RPV is heavy-tailed and mostly zero: the large majority of sessions spend nothing, and a small handful spend a lot, with the occasional $300 order sitting far out on the tail. That spread makes RPV noisier, so it needs more traffic to reach the same confidence, and it needs outlier handling. The standard discipline is to winsorize at the 99th percentile (cap each session's revenue at the P99 value) so a single whale order can't fake a win that won't repeat. Treat AOV as a guardrail you watch, and make your ship-or-kill call on RPV.
The same logic explains why you should distrust any test result quoted on a step before the sale. "Add to cart up 12%" is not "revenue up 12%," and the gap between them is bigger than most merchants assume. Add-to-cart rate and orders correlate at only about R = 0.50 across GoodUI's test set (n = 44), which means add-to-cart explains roughly a quarter of the variation in actual sales. A separate Conversion.com analysis puts the add-to-cart link near R = 0.43 (n ≈ 200). The further down the funnel you measure, the more trustworthy the read: checkout visits track sales at about R = 0.61 in Conversion.com's larger set (n = 533). Closer to the money, closer to the truth.
This is why a careful tool discounts a projection built from an add-to-cart lift more aggressively than one built from a checkout lift. The correlations above act as an honest ceiling on how much of a proximate gain you can expect to pass through to revenue, and they are cross-store calibration, not your store's own result. They widen the range we quote you; they never tighten it. The figure below shows the discount trap end to end: the conversion-rate pair fills first with its tempting tag, then the revenue-per-visitor pair flips the verdict.
Control
3.0% conversion rate
$80 average order
$2.40 per visitor
Variant: "10% off, next 10 minutes"
3.6% conversion rate (+20%)
$62 average order
$2.23 per visitor
Conversion rate up 20 percent. Revenue per visitor down. A conversion-rate tool calls this a winner. An honest one does not ship it.
The practical rule is short. Run every test on revenue per visitor. Keep conversion rate and average order value on screen as guardrails so you can see how a change earned or lost, but never let either one cast the deciding vote. When a result reads great on conversions, that is exactly the moment to check what happened to order value, especially for anything that touches price, urgency, or the cart. The cleanest place to watch this in action is the path from cart to checkout, where small offers can swing both numbers in opposite directions; we cover that in cart and checkout friction.
What should you A/B test first on your Shopify store?
Start where the money leaks, not where the change is easy. In our 2026 audit of 1,000+ live Shopify stores, 93% had at least one visible conversion leak on arrival, and the most common ones live on the product page and the cart. Those are also the surfaces you can test on any Shopify plan, which makes them the obvious wedge. Pick your first test by working down from the leak with the highest chance of a meaningful lift, not the one that takes ten minutes to ship. A button color rarely moves money. A buried buy button on mobile almost always does. Sequence your queue by evidence, expected size of the effect, and effort, in that order.
One thing to hold onto before any of the ideas below: a test can lift add-to-cart and still lose on revenue per visitor. That is why the verdict is always RPV, never the proximate click. And every lift range I give you here is a cross-store calibration prior, not a promise for your store. Most tests do not win. The ranges tell you where to point first; your own data tells you whether it actually paid off.
I will group the rest into four clusters. Each idea uses the same five-part shape we use inside StorePilot: what is wrong, why (the evidence or the segment), what to test, how much it could earn (as a range, read on RPV not on add-to-carts), and the risk or effort. Work top-down.
Cluster A: the mobile buy-flow. Start here. The audit makes this the most defensible "begin with this" of all, because most of your traffic is on a phone and that is where the buy decision actually happens.
- Sticky Add-to-Cart bar on mobile. What is wrong: 65% of stores bury Add to Cart below the fold on mobile, so a shopper has to scroll back up to buy. Why: the buy moment passes and they leave. What to test: a thin bar that pins the price and the Add to Cart button to the bottom of the screen as they scroll. How much: in our cross-store experience this lifts mobile add-to-cart roughly 5% to 15%, which reads through to something like +3% to +8% RPV after the usual attenuation, most likely in the middle of that band. Read it on RPV, not on the add-to-cart bump. Risk: low, fully reversible.
- Add to Cart above the fold on mobile. What is wrong: 23% of stores show no clear call to action above the fold. Why: the first screen sells nothing. What to test: move the price and buy button up so the shopper sees them without scrolling. Risk: low.
- Mobile page speed and image weight. What is wrong: 37% of stores load slowly on mobile, and slow pages quietly shed buyers. Why: every extra second loses people before they ever see the product. What to test: compress and right-size the hero and gallery images. This one is usually better measured with apply-and-measure against your real LCP field data than with a clean 50/50 split, because the gain shows up in load timing, not just in clicks. Risk: low to medium.
- Inline variant buttons instead of a dropdown. What is wrong: size and color hidden inside a tap-to-open dropdown add friction on a phone. What to test: lay the options out as visible, tappable buttons. Risk: low.

If your store is below roughly ten thousand sessions a month on these pages, do not let "not enough data yet" stop you. These mobile changes are bold and structural, which is exactly what low-traffic stores should test: a big swing needs far less traffic to read than a 2% tweak. Ship to most of your traffic, keep a holdback on the old version, and judge the two on revenue per visitor. The lift ranges above are calibration, not a forecast.
Cluster B: trust and reassurance at the buy moment. People hesitate right before they commit. Small honest signals near the button close that gap.
- A reassurance line under Add to Cart. What is wrong: 31% of stores show nothing reassuring near the buy button. Why: a first-time shopper does not know your returns or shipping policy and bails rather than risk it. What to test: one short, true line under the button, such as free returns or a delivery window. Risk: low.
- Star rating and review count above the fold. What is wrong: about 14% of stores show no visible reviews. Why: a price with no proof beside it reads as a gamble. What to test: surface the average rating and the count of reviews up by the title. Risk: low, assuming the reviews are real.
- Photo and UGC reviews. What to test: pull customer photos into the review block so the proof is shown, not just counted. Risk: low.
- An honest delivery-date promise. What to test: a real, accurate "arrives by" date near the button. Keep it true to your fulfillment, never an invented deadline. Risk: low if your dispatch data is reliable.
Cluster C: average order value and cart-level RPV. These are where you grow the money per buyer, but they are also the easiest place to lift a vanity metric while shrinking margin, so the RPV discipline matters most here.
- Free-shipping threshold and progress bar. What is wrong: 60% of stores show no free-shipping threshold to nudge order value. What to test: set a sensible threshold and show a progress bar ("you're $12 away from free shipping"). Why it works: it gives shoppers a reason to add one more item. The catch: watch your shipping margin against the AOV gain, and judge it on RPV, not on AOV alone. Risk: medium, because a badly set threshold can cost you margin.
- A relevant cart cross-sell. What to test: one genuinely complementary product offered in the cart. Relevance is the whole game. Judge it on incremental RPV, not on attach rate, because an attach that would have happened anyway is not new money. Risk: low to medium.
- An impulse add-on. What to test: a small, low-friction extra such as gift wrap, a sample, or a warranty. This is the safest AOV test because it adds money without discounting anything. Risk: low.
- Per-unit or multi-pack "best value" framing. What to test: a "buy three, best value" option with the per-unit price shown. Risk: low.
Cluster D: checkout entry. These sit closest to the money, and changes this near the purchase read through to revenue more reliably than anything higher up the page. That also makes them strong low-traffic candidates, because the signal is cleaner.
- Express checkout buttons. What to test: surfacing Shop Pay, PayPal, and Apple or Google Pay near the buy button so returning shoppers skip the form. Why: one tap beats a full checkout for a lot of mobile buyers. Risk: low.
- Guest checkout prominence. What to test: make checking out as a guest obvious rather than forcing an account first. Risk: low.
A reminder, because it is the one that saves you from a bad ship: even on these last-mile changes, "add-to-cart up 12%" is not "revenue up 12%." We read RPV, not add-to-carts. The closer a test sits to the money, the more its lift survives the trip to the bank, but it still survives as a range, with a confidence interval, not as a point estimate.
One note on urgency, because it is a fork in the road. Real low-stock pulled from live inventory and a real dispatch cutoff are honest and worth testing. A countdown that resets when you reload, or "5 people are viewing this" invented out of nothing, are not. Same spot on the page, opposite ethics. The honest versions tend to hold up over time; the fake ones win a short bump and then erode trust, refunds, and repeat purchases, which an RPV-on-one-window test will not even show you. We do not test the fake kind.
What about the homepage, collection pages, and search? They matter, but they sit higher up the funnel, the effect is more diffuse, and they are harder to read at small traffic. Treat them as what comes next after the product-page-and-cart wedge has earned its first wins, not as where you begin.
All four clusters tie back to the deeper playbooks. The mobile buy-flow tests live in mobile conversion. Reassurance and reviews are covered in social proof and trust. Layout and variant changes belong to product page optimization. Thresholds, cross-sells, and bundles are in average order value. And the cart, checkout, and guest-checkout work sits in reducing cart abandonment. Start with one leak, test it honestly, keep it only if it beats your own baseline on revenue per visitor, then take the next one.
How does an A/B test actually work on Shopify (mechanically)?
A Shopify A/B test splits your sessions into groups, shows each group a version of one page, keeps every shopper sticky on the version they first saw, and measures revenue per visitor for each. Two facts about Shopify shape every method that does this. Your store only ever serves one published theme at a time, and the checkout is locked down on standard plans. So the real question is not "can I split traffic," it is "where does the variant get built, when does it appear, and what does it touch." Get that wrong and you either bias the test or break the store. A variant, by the way, is just a controlled second version of one page, not surgery on your whole store. The original stays live for the control group the entire time.
There are five ways a tool can pull this off on Shopify, and they are not equal. They differ in how risky they are, how fast the variant appears, and what it does to your search rankings. Here is each one in plain terms, with what it means for you.
1. Theme duplication. The tool copies your live theme, edits the draft copy, and serves the draft to the variant group. High fidelity, because the variant is a real theme, but heavy and slow to set up. The catch is technical and quiet: the ?preview_theme_id= query string that points a visitor at the draft theme is lost the moment they click to another page. Without a sticky cookie or localStorage flag holding each visitor on their assigned version, people bounce between control and variant mid-visit and the data turns to mush. What this means for you: fine for a big redesign, overkill for changing a button, and only safe if the tool sets a sticky cookie.
2. Split-URL / redirect. The variant lives at a different URL and a share of visitors get redirected to it. This is the SEO landmine, and it is worth slowing down on because it is the one that can quietly cost you rankings. Two URLs with near-identical content read as duplicate content to Google, so the variant needs a rel=canonical tag pointing back to the original. The redirect itself must be a 302 (temporary), never a 301 (permanent), or Google may de-index your real page and keep the test URL instead. And the test URLs have to stay out of your sitemap. Redirects also add a beat of latency, which is the number-one cause of an uneven split. What this means for you: only for radically different layouts, and only with a tool that handles canonicals, 302s, and sitemap exclusion for you. If it does not, walk away.
3. Client-side JavaScript swap, and the flicker problem. The page loads your control first, then a script rewrites it into the variant after the fact. The shopper sees a flash of the original before it changes. That flash is called FOUC (a flash of unstyled, or in this case un-swapped, content), and it only happens to the variant group, which biases the test against your variant before a single number is counted. The standard fix is an anti-flicker snippet that hides the whole page until the script runs. It works, and it carries a cost. In one DebugBear test, the anti-flicker snippet pushed render start from 4.1 seconds to 5.1 seconds, a full second of blank screen. So the cure inflates your largest contentful paint, slows the variant differently from the control, and that load-speed gap is itself a documented way for the split to come out wrong. The fix can corrupt the data it was added to protect. What this means for you: tolerable for quick small changes if you accept the speed tax, dangerous on mobile, and never how you want to run an important test.
4. An app via theme app extension, App Proxy, and Web Pixel. The modern, Shopify-blessed way. The variant is delivered through app blocks and embeds that you toggle on in the theme editor, so the tool edits zero theme files and every change is fully reversible. Because the block is part of the page the server renders, the variant is present at first paint. No flash, no anti-flicker snippet, no speed tax. The App Proxy serves the variant configuration from under your own store domain (HMAC-signed, so it is verified as genuinely from the app), which keeps it first-party and fast. This is how StorePilot works. What this means for you: the variant shows up clean and instant, your theme files are never touched, and you can roll back with a toggle.
5. Sticky deterministic bucketing. This is the plumbing underneath all of the above, and it is where amateur tools give themselves away. A visitor gets assigned to control or variant by hashing a stable visitor ID together with the experiment ID, then taking that result modulo 100: hash(visitorId + experimentId) % 100. The same visitor always lands in the same bucket, on every page, every visit. What you must never do is call Math.random() on each page load, because then a single shopper sees the control on the homepage and the variant on the product page, and your test is measuring nothing. The assignment happens before anything visible changes, and the same answer is shared between the surface that renders the change (the theme extension) and the surface that measures it (the Web Pixel). What this means for you: ask any tool whether a returning visitor always sees the same version. If the honest answer is no, the results are noise.
Two more things hold this together: how the measuring is done, and how the store stays safe.
The measuring runs through Shopify's Web Pixels, not a script someone bolted onto your theme. App pixels run in a strict sandbox, a Web Worker with no access to the page's DOM, so a tracking tool cannot read or tamper with your store. They are consent-gated, meaning the tracking callbacks only fire after a shopper has given consent, and they replay once consent is granted so you do not lose the data. Shopify has also been tightening protected-customer-data rules on what pixels may collect (confirm the current state on Shopify's changelog before you rely on it). The plain version: a good Shopify testing tool does not strap tracking onto your store, it uses Shopify's own consent-aware pixel.
Only one theme is ever live. So staging the variant on a draft, previewing it before you publish, and being able to roll back in one click are not nice-to-haves. They are the whole safety model. If a tool edits your theme files directly, that is the thing to be afraid of.
That theme-safety point is the one to keep. A reversible change toggled through a theme app extension can be undone instantly and never leaves a trace in your code. A tool that rewrites your .liquid files to insert a variant can leave you with a broken theme and no clean way back, especially if the test ends badly during a busy week.
Here is how the five methods compare on the things that actually decide which one is safe for your store.
| Method | Works on | Variant at first paint? | SEO risk | Best for |
|---|---|---|---|---|
| Theme duplication | All plans | Yes | Low | Big redesigns |
| Split-URL / redirect | All plans | Not applicable | High | Radically different layouts |
| Client-side JS swap | All plans | No (flicker) | Low, but a speed tax | Quick small changes |
| Theme app extension + App Proxy + Web Pixel | All plans (storefront) | Yes | Low | The modern Shopify way |
| Checkout test | Plus only | Not applicable | Not applicable | Checkout flow |
If you remember one line from this section: the method that wins on Shopify is the one that builds the variant into the page the server already renders, shows it at first paint, never touches a theme file, and keeps each shopper on one version. That is also why the checkout, which Shopify shares across every theme version and guards closely, needs its own approach. We cover where price and checkout testing actually become possible in the next section. For the speed side of the flicker problem, which hits hardest on phones, see mobile conversion. For testing on the cart page specifically, see reducing cart abandonment.
Which Shopify A/B testing apps are worth it (and what about checkout and pricing)?
The right tool depends entirely on what you want to test: your theme and layout, your prices, or your checkout. There is no single best app. There is a best app for the change in front of you, the plan you are on, and how much traffic that page sees. And one hard rule sets the boundary before you compare anything else: on standard Shopify plans you cannot test your checkout at all. That pushes the whole opportunity onto the surfaces you can touch on every plan, which is exactly why the smart starting point for almost every store is the product page and the cart.
Start with the wall, because it decides half the question for you. Shopify is closing off the old ways merchants customized checkout. The checkout.liquid file and the additional scripts on the thank-you and order-status pages were sunset on August 28, 2025. The remaining checkout customizations are scheduled to stop working across all plans by late August 2026 (Shopify's own checkout.liquid documentation is the canonical source here, so verify the live deadline against it rather than treating any date as fixed). Shopify Scripts reach end of life on June 30, 2026. The replacement for all of it is Checkout Extensibility: UI Extensions for the interface, Web Pixels for tracking, and Functions for discount and shipping logic.
What that means in plain terms: meaningful checkout testing is effectively Shopify Plus only. If you are on a standard plan, the checkout is a sealed box. You can watch what happens inside it, but you cannot run a variant against it. Everything storefront-side is a different story. Your product pages, collection pages, cart page, and homepage are testable on every plan. So the wedge, the place where a small store actually has room to work, is the product page and the cart. Not because they are the most exciting surfaces, but because they are the ones you are allowed to change.
The checkout is locked on standard plans. The product page and cart are not. That single fact, more than any feature list, decides where most merchants should test first.
Price testing is the other question people assume is impossible, and it is not. You can A/B test prices on Shopify. Intelligems is built specifically for it, working around the platform's price-test limits through cart-transform functions. The discipline is the same one that runs through this whole guide: judge a price test on revenue per visitor, never on conversion rate. A lower price almost always lifts conversions while quietly shrinking your margin, so a price test that "wins" on conversion can lose you money on every order. Shopify also requires that prices stay consistent within a shopper's session and that they are real, not bait-and-switch numbers. Test honestly and read it on RPV.
Here is how the main options compare. Prices are stamped as of June 2026 and you should verify them live, because tool pricing moves and most of these meter on different things (orders, visitors, or tested users), which changes the real cost more than the headline number does. For the full app-by-app breakdown of all eight tools, see the best Shopify A/B testing apps compared.
| Tool | Best at | Rough price | Low-traffic fit | Fair limitation |
|---|---|---|---|---|
| Shopify Rollouts (native) | Free, safe theme traffic-splitting and rollback | Included; split analytics need Grow or higher | Poor (no stats) | No significance, no winner, no checkout, pricing, or segmentation |
| Intelligems | Price, offer, and profit testing | Core ~$59 to $79, Plus ~$374 to $499, Blue ~$749 to $999/mo | Moderate | Price testing sits on the pricier tiers; meters on storewide orders |
| Shoplift | Theme, template, and page tests | From ~$74 to $99/mo, scaling with visitors | Decent | Visitor-based pricing climbs; it still leaves the call to you |
| Visually.io | Testing and personalization, no-code | Order-volume based, no fixed entry price | Accessible entry | Ships countdown and urgency widgets, a philosophy we do not share |
| Convert Experiences | Standalone full-featured testing | Growth ~$399 ($299 annual), Pro ~$599/mo | Volume-bound | Not Shopify-native; sequential and raw export gated to Pro and up |
| Optimizely | Enterprise experimentation | Reported ~$40k to $150k+/yr (unpublished) | Not applicable | Cost and complexity are overkill for most DTC stores |
| Clarity / Hotjar / Lucky Orange | Watching behavior (heatmaps, recordings) | Clarity free; Hotjar free to ~$32+/mo; Lucky Orange ~$39 to $839/mo | Not applicable | They show you what happens, never what to do or whether it made money |
| CRO agencies | Done-for-you human strategy | ~$2k to $35k+/mo, often 6-month minimums | Same math limit | Expensive, slow to start, and you rent the expertise |
Two questions sort the whole list. The first is whether a tool observes or acts. Heatmap and session-recording tools (Microsoft Clarity, Hotjar, Lucky Orange) show you what shoppers do. They are genuinely useful for forming a hypothesis. They will never tell you what to change or whether a change made you money. That is the line between watching behavior and running an experiment against it. The second question is whether a tool needs big traffic or works on the traffic you actually have. Classic A/B apps with full stats engines (Convert, Optimizely) assume enterprise volume; below it they leave you stuck on "not enough data yet" forever.
Plot those two axes and most tools cluster in the same corner: they act only if you bring the strategy, and they expect traffic most Shopify stores do not have. StorePilot's lane is the opposite corner. The software does the acting, it is built to work on low traffic through honest methods (apply-and-measure, holdbacks, cross-store priors), and it reports results the honest way: revenue per visitor as the verdict, calibrated confidence in words rather than a raw p-value, a projected-dollar range instead of a single number, and a plain "how we estimate this" on every figure. It only proposes changes that fit your brand, so dark patterns never make it into a test in the first place.
None of that competes with Shopify Rollouts. It sits on top of it. Rollouts is a good, free, server-side traffic splitter with safe rollbacks and no flicker, which is exactly the plumbing an honest test needs. What it does not do is decide what to split or tell you whether the result was real. So the cleanest setup is to use Rollouts as the safe splitter and let the brain decide what to test and judge whether it won. One rule holds no matter how much AI is in that loop: the winner call itself stays deterministic math, never a language model's opinion. Why that line matters is the whole subject of Never let an AI decide your A/B test. If you want the longer version of how the software finds the fix and runs the test, that is covered in AI that finds the fix and runs the test, and the mechanics of how the platform tests on your behalf are in how it works.
The practical takeaway is short. Match the tool to the job. Use Rollouts as a free, safe splitter for theme and layout changes, and if the change you are weighing is the whole theme, a redesign or a switch to something new, that test has its own mechanics and its own traps, which we walk through in the Shopify theme A/B testing playbook. Reach for Intelligems when the test is about price or offer. Bring in a standalone tool like Convert or Shoplift if you have the traffic and want a full stats engine you drive yourself. Keep the observe tools (Clarity is free and excellent) for finding problems, not deciding them. And remember the boundary that started this section: until you are on Plus, the checkout is off the table, so put your energy where you are actually allowed to test, which is the product page and the cart.
How do you read A/B test results honestly?
A result is real when it survives a short checklist, not when the dashboard turns green. Decide on revenue per visitor, confirm the test was actually valid, check whether your segments tell a different story, then translate the lift into dollars before you ship anything. The order matters. Most bad calls come from skipping straight to the percentage at the top of the screen.
Here is the checklist we run before we believe any A/B test result. Walk it top to bottom every time.
- The test ran at least one full business cycle, ideally two weekly cycles, so weekends and paydays are represented on both sides.
- No sale, promo, press hit, or ad spike contaminated the window.
- The split came out as designed (the SRM check passed, more on that below).
- Revenue per visitor (RPV) is the verdict. Conversion rate and average order value are guardrails, not the call.
- The confidence interval on RPV excludes zero.
- The result is not driven by one or two whale orders.
- You broke it out by device and the segments agree.
- The effect is not decaying week over week (not just novelty wearing off).
- You translated the lift into "+$X to +$Y per month" before deciding.
If a result fails any of these, it is not a winner yet. It is a candidate.
Why segments can flip the whole verdict
A variant can win in every single segment and still lose on the blended number. This is Simpson's paradox, and it is not a curiosity. It quietly mislabels real winners as losers on Shopify all the time, because mobile and desktop convert at very different rates and the traffic mix shifts during a test.
Here is a worked case. On desktop, version A converts at 6.0% and version B at 6.5%. On mobile, A converts at 2.0% and B at 2.2%. B wins both segments. But if the variant happened to pull a heavier share of mobile traffic, the blended rates can land at A 4.86% versus B 3.43%, and the dashboard declares A the winner. The segment truth is the real one. B is better; the blend lied because the mix moved.
The blended average is where good tests go to die. Pre-declare your segments, then trust the segments over the blend.
The discipline: name two or three segments before you start, with device as non-negotiable. Do not slice twenty ways after the fact hunting for a green number. That is fishing, and with twenty slices one of them looks significant by pure chance.
SRM: the check that tells you the test was broken
Sample Ratio Mismatch is the most important check almost nobody runs. You designed a 50/50 split. If the traffic actually landed 54/46, something is broken: a redirect dropping visitors, bots hitting one side, flicker scaring people off the variant, or a tracking bug. With a few thousand visitors per side, a 54/46 split is not random drift. It is a red flag.
Use a strict alarm threshold of p < 0.01. If SRM fires, do not interpret the result. Throw the test out and find the cause. A broken assignment can produce a beautiful, confident, completely fake winner. Filter bots equally across both versions so you are not cleaning one side and not the other.
Novelty, and statistical versus practical significance
Read week one and you are measuring how your regulars react to change, not the steady-state value of the change. Returning visitors notice that something moved; new visitors have no "before" to react to, so they are the cleaner signal. Watch whether the lift holds into week two. If it fades, it was curiosity, not value. Ship only what persists.
Then separate two things people constantly blur. Statistical significance means the difference is probably not luck. Practical significance means it is big enough to bother building. With enough traffic, a +0.4% lift can hit 99% significance and still not be worth an afternoon of work. Set a practical threshold up front, and report the result as a dollar range, never a bare p-value or a lone percentage.
This is why we report calibrated words instead of a raw statistic a merchant will misread. Exploratory means replicate before acting. Likely means proceed, but keep monitoring. Strong means ship. And "strong" is earned from track record, not asserted from one good-looking test. The projected dollars are always a range pulled from the merchant's own data; StorePilot will not emit a point estimate, because a point estimate is a promise nobody can keep.
Reading one result end to end: a free-shipping bar
Put it together on a real store. Say a skincare brand runs a 4% conversion rate, a $55 average order value, and about 25,000 sessions a month. The hypothesis is that a free-shipping progress bar in the cart lifts revenue per visitor. The owner sets the finish line before launch: ship only if RPV improves by 5% or more, and the tool shows up front that this will take roughly three to four weeks at that traffic.
The test runs two-tailed for a minimum of two weeks. First check: SRM lands at 50.2/49.8, healthy. RPV reads up 6%, with a confidence interval of +1% to +11% that excludes zero. AOV is up 9% and conversion rate is down 1%, but that CVR change has a confidence interval that includes zero, so the guardrail is fine. The lift is not whale-dominated. The honest verdict word is "likely," not "strong," because one test at this traffic does not earn "strong."
So it ships, but with a 10% holdback to confirm the lift holds past the novelty window, and the owner banks the late-window stabilized estimate rather than the early peak. The reading near a result like this is exactly the trap the hero illustration warns about: the band that looks like a winner on day four often is not one on day eleven.
Watch a test long enough and random swings will cross your significance line on their own. Day 4 it looks like a winner. Day 11, the same test, it is back to nothing.
The discount mechanics under a free-shipping bar are why RPV, not conversion rate, is the verdict here; we go deeper in how to raise average order value. And because the desktop-versus-mobile reversal is the single most common way segments flip a call, it is worth understanding how mobile converts differently before you trust any blended number.
What are the most common Shopify A/B testing mistakes?
A badly run test is worse than no test. No test leaves you guessing and knowing it. A bad test launders that same guess into a "data-backed decision," and a decision wearing a lab coat is much harder to argue with. The mistakes below are the ones we see again and again, and almost all of them push the result in the flattering direction: toward a win that was never really there. For each one, here is the symptom you would notice, why it fools you, and the single thing to do differently. None of this requires more math than you already have. Most of it is just deciding the rules before you look at the score.
A test that is allowed to lie is more dangerous than no test, because it makes a guess wear a lab coat.
The twelve that cost merchants the most:
- Peeking, then stopping early. The original sin. You check the dashboard daily, B is ahead on day four, you call it. The problem: random swings look exactly like real wins early on, and every extra look is another chance to get fooled. Peek daily for two weeks and your real false-positive rate climbs from the 5% you signed up for to about 26% (Evan Miller's canonical figure; 20 to 30% and up under continuous monitoring). Fix: set the finish line before you start, sample or duration, and do not call it before you hit it. If you must watch live, use sequential math built to survive being looked at.
- Testing too many changes at once. You rewrite the headline, recolor the button, and add a badge, B wins, you ship all three. You learned the bundle won, not which part. Changes also cancel: a headline worth +12% and a button worth −8% nets a muddy +4%, and you keep the loser by accident. Fix: one hypothesis per test. Bundling is fine only when every change serves the same single idea.
- Chasing conversion rate instead of revenue per visitor. The discount illusion. A "10% off" banner lifts conversions and a conversion-rate tool throws confetti, while average order value quietly drops and you make less money. Fix: judge on revenue per visitor, every time. And never read a proximate lift as a dollar lift one-for-one. Add-to-cart and orders correlate only around R 0.50 (GoodUI, n=44), so "add-to-cart up 12%" is not "revenue up 12%."
- Ignoring segments. A flat blended average can hide your best discovery: a change that wins big on mobile and loses on desktop reads as "no effect." Fix: break results by device at a minimum, declared up front. When a variant wins one segment and loses another, that conflict is a finding. Ship it where it wins.
- Underpowered tests. At a 2.5% baseline, detecting a +5% lift needs roughly 100,000 visitors per variant. Run it on a fraction of that and you get "inconclusive," which everyone misreads as "no difference" and files as proof. Fix: do the power calc first. If the traffic is unreachable, do not run a classic A/B test; use the low-traffic path instead.
- Sample ratio mismatch. You set a 50/50 split and it lands 54/46. That gap means assignment is broken (a slow redirect, bots, flicker, a tracking bug), and a broken test can still show a beautiful winner. Fix: check the split before you read significance. If it is off past a strict threshold, throw the test out. Do not interpret it.
- Novelty and change aversion. Regulars react to anything new, up or down, and that reaction fades. Read week one and you measured surprise, not steady-state value. Fix: run through the curiosity window and watch new visitors separately, since they have no "before" to react to. Ship only if the lift survives.
- Running through a sale or holiday. Promo traffic shops differently: more discount-hunters, different intent, abnormal volume. A result baked during a sale tells you nothing about a normal Tuesday. Fix: do not start a test you cannot finish before a promo, and discard any window a promo contaminated. A sale should only widen your uncertainty, never tighten it.
- HARKing (deciding the hypothesis after you see the results). Slice twenty segments and one will look significant by pure chance, then you write the story backward to fit it. Fix: pre-register the hypothesis, the primary metric, and the two or three segments before launch. Anything you find after that is a lead for the next test, not a conclusion from this one.
- Confusing statistical with practical significance. With enough traffic a +0.4% lift can hit 99% confidence and still not be worth the hours to build. Fix: set a practical minimum (the smallest lift that justifies the work) up front, and report the result as a dollar range, not a bare percentage or p-value.
- Flicker contaminating the data. A client-side test renders the original first, then flashes in the variant. Only B's visitors see the flash, and that flash biases the test against B, worse on the 37% of stores that load slowly on mobile in our 2026 audit of 1,000+ live Shopify stores. Fix: serve variants server-side or through a theme app extension so the variant is there at first paint, with no injected scripts to flash.
- Not covering full business cycles. Tuesday shoppers and Saturday shoppers buy differently. End on day five and you measured one slice of the week. Fix: run at least one full week, ideally two. Minimum duration is a separate gate from minimum sample and from significance, and you have to clear all three before you call anything.
Two more that are less about a single test and more about the habit around it. First, you never validated your tracking, so when something breaks you cannot tell. The fix is an A/A test: run the same version against itself. If "B" wins an A/A, your measurement is lying and every test you have ever run is suspect. Second, you quit after one inconclusive result. Most changes do not win, which is exactly why one test proving nothing is normal, not a verdict on testing. Conversion work is a program with a backlog, not a single pull of a lever.
Below is the peeking trap drawn out: the same test, watched too early and then left to finish.
If you take one thing from this list: the test does not protect you, the rules you set before the test do. Decide the finish line, the metric, and the segments in advance, gate out the tactics you would be ashamed to defend, and read the result on revenue per visitor. The flicker and mobile-specific traps connect to mobile conversion, and the underpowered-test problem is exactly why low-traffic stores need a different method, covered in the low-traffic section above and in the broader Shopify CRO playbook.
Does A/B testing hurt your Shopify SEO?
Done right, no. Done carelessly, yes. A clean A/B test is invisible to Google. The damage only shows up in three specific places: duplicate content from split-URL tests, the wrong kind of redirect, and the page-speed hit from flicker. All three are avoidable, and the safest setup happens to also be the safest for your store.
Split-URL tests put the variant on a separate web address. Google can find that second address, decide it competes with your original, and split or move your ranking. Three rules keep you safe. Put a rel=canonical tag on the variant pointing back to the control, so search engines know which one is the real page. Use a 302 (temporary) redirect, never a 301. A 301 tells Google the move is permanent and can quietly de-index your original page, the one you actually rank with. And keep every test address out of your sitemap so you are not inviting Google to crawl pages that should not exist for long.
The redirect setting is one character of difference on paper and a ranking you spent two years earning in practice. Use the 302.
The bigger, quieter risk is speed. Many client-side testing tools render your normal page first, then swap in the variant, which causes a visible flash. The common fix is an anti-flicker snippet that hides the whole page until the test loads. That hiding inflates Largest Contentful Paint, one of the Core Web Vitals Google measures, by the same render-start penalty we saw in the mechanics section (4.1 seconds to 5.1 seconds in DebugBear's test, a full extra second before anything appeared). You are trading a ranking signal to cover up a testing weakness. Server-side methods (native Rollouts, theme-native tools like Shoplift, and theme app extensions) build the variant before the page paints, so there is no flash and no anti-flicker tax at all.
Speed is worth caring about beyond SEO, because it moves money directly. In Deloitte and Google's "Milliseconds Make Millions" study (2020, 37 retail and travel brands, mobile, correlational), a 0.1-second improvement in load time lined up with a +8.4% lift in retail conversions. Portent's data shows the same shape from the other direction: ecommerce conversion rate roughly halves as load time slips, from 3.05% at one second to 1.68% at two seconds, then 1.12% at three and 0.67% at four. These are correlations across many sites, not a promise for yours, but the direction is consistent and the cost of a slow page is real.
The thread tying this together is theme-safety. A testing method that edits your live theme files, or spins up indexable duplicate pages, is the one that puts your SEO at risk. A reversible, preview-before-publish, server-side approach leaves no orphaned test URLs for Google to crawl, adds no anti-flicker delay, and rolls back in one click if a variant misbehaves. The SEO-safe way to test and the merchant-safe way to test are the same way.
So the honest answer for a Shopify merchant: testing will not cost you rankings if you canonical your split-URL variants, redirect with a 302, keep test pages out of the sitemap, and avoid client-side flicker by testing server-side. Get those right and search and testing stay out of each other's way. For the wider picture on how speed, page structure, and trust all feed conversion, see the conversion fundamentals.
How do you build a repeatable Shopify testing program (and is it worth it vs more ads)?
Testing pays when you treat it as a queue, not a one-shot, and optimizing the traffic you already paid for usually beats renting more of it. The reflex when sales stall is to spend another $500 on Meta. But ad spend buys one batch of visitors once. A real conversion win works on every visitor after it, including all the ones those future ads bring in. That is the difference between renting growth and owning it. A program that ships one honest test after another, ranked by evidence, compounds. A single test you run, win or lose, then abandon does not.
Look at the back-of-envelope math, because it cuts both ways and I want to be straight with you. Say you do $15,000 a month at a 2.4% conversion rate. A realistic 10% lift in revenue per visitor is worth roughly $1,500 a month, and it keeps earning on traffic you have not paid for yet. A testing tool runs around $299 a month plus maybe three hours to set up. If you win in the first two or three months, it pays back inside a month. That is the optimistic story.
Here is the honest one. Most tests do not win, so you do not get a payoff on attempt one. If it takes about eight tests to land a single real winner, you are paying five or six months of fees, call it $1,500 to $1,800, before the first dollar comes back. No competitor guide tells you that part. I will, because if you walk in expecting an instant win you will quit right before the program starts working.
The win rates back this up, and they are a spread, not one confident number. Depending on the source, somewhere between roughly 1 in 7 and 1 in 3 tests produces a real winner. VWO puts it near 1 in 7, though they publish no methodology behind that figure. DRIP's data splits more honestly: across their tests, 36.3% were significant winners, 22.1% were significant losers, and 41.6% came back inconclusive, on a median 42-day run. So more than a fifth of the time, the change you were sure about actively hurt. That is exactly why you test instead of ship on a hunch.
And the wins that do land are usually modest. Convert's 2026 data shows 84% of winning tests came in under a 50% lift, and 60% under 20%. So plan for singles, not home runs. The practical takeaway:
- Keep a backlog of at least 16 evidence-ranked ideas, because you need roughly that many shots to bank around two meaningful wins.
- Rank each idea by evidence times expected effect times ease, and run your highest-evidence leaks first. The ones your own audit surfaced go to the top of the queue.
- Use a method or tool that costs less than two wins are worth, so the math stays in your favor even when most tests come back flat.
You already paid for the traffic. A conversion program is the one growth lever that makes every past and future ad dollar work harder, instead of just buying more of the same leaky visit.
It helps to know how rare this discipline still is. By BuiltWith's count, only about 0.2% of all websites run any A/B testing tool at all. Among the top 10,000 sites it is roughly 32%, but it drops to about 11.5% across the top million. Testing has been a big-store luxury, and that gap is the opening. (Fair caveat: BuiltWith detects client-side tools, so server-side and native testing slip past it, which means the true number is a bit higher.) The point stands. Most of your competitors are still guessing.
The loop itself is simple, and it is the whole program. Watch how shoppers behave. Form one specific guess about what is costing you sales. Test it honestly, on revenue per visitor, with the finish line set before you start. Then keep only the changes that beat your own baseline on real money, and feed the rest back into the queue as lessons. Repeat. The animation below is the honest version of that loop, where the check mark only appears after the result actually crosses the line, not before.
Watch, vary, measure, confirm. The check earns its place at the end, not at the first good-looking moment.
You do not need a developer to run any of this. With a tool built on a Shopify theme app extension, the variant is built for you and you approve the test, you do not write the code. Your job is to keep the queue stocked and judge each result honestly. For the broader picture of how this connects to everything upstream, see the CRO loop. And if you want the base rates that decide where your first few tests should aim, start with the numbers behind Shopify conversion.
How does StorePilot do honest A/B testing for you?
StorePilot is the part that acts. It finds the friction on your store, writes the fix up as an Opportunity (Problem, Evidence, Fix, projected-dollar range, Risk), generates the actual variant, runs the test the honest way, and helps you publish the winner. Every verdict is read on revenue per visitor, not a vanity conversion rate. You approve; you do not build.
Everything in this guide is the method. StorePilot is the method running on its own, on your store, all the time. Here is how each piece maps to what you just read.
It acts, it does not just watch. Heatmap and recording tools show you what happens. StorePilot decides what to do about it and runs the test that proves whether it helped. That is the line between an observe tool and an act tool, and StorePilot sits on the act side.
It is built for your real traffic. Most Shopify stores are below textbook significance traffic, so StorePilot does not pretend otherwise. It runs apply-and-measure with a holdback, leans on calibrated cross-store priors to widen (never tighten) its estimates, and shows you the time-to-result at your actual session count before you commit to a test. If a clean A/B test is not reachable, it tells you and switches method instead of saying "not enough data yet" forever.
The stats are honest by construction. StorePilot uses anytime-valid sequential math, which means peeking at the result early cannot inflate the false-positive rate the way it does with a fixed-horizon test. It reports confidence as calibrated words (exploratory, likely, strong), never a raw p-number you might misread, and "strong" is earned from track record, not asserted from a single run. The projected payoff is always a range from your own data, with a plain "how we estimate this" attached. It refuses to emit a point estimate.
We will not show you a fake early winner, a single confident number, or a lift without its range. If a test cannot be judged honestly at your traffic, we say so and change the method.
It only tests on-brand changes. Your Brand profile filters dark patterns out before they are ever tested. Real low stock from live inventory and a real dispatch cutoff are fine. Fake countdowns and "5 people viewing" lies are refused. A test that "wins" by tricking shoppers is blind to refunds and lost repeat buyers, so we keep it off the board.
It is theme-safe. Changes ride a theme app extension: reversible, backed up, preview-before-publish, one-click rollback, never a destructive rewrite of your theme files. Tracking runs through Shopify's own consent-aware Web Pixel, sandboxed, not a script bolted onto your storefront.
StorePilot is built at EVDEV, where we have spent 7+ years doing hands-on Shopify conversion work, and the CRO logic is shaped by Misha Gavura. The honest-first stance is not marketing. It is the only way the numbers stay worth trusting.
If you want to see it on your own store, you can start testing free for three months, or read how the testing loop works first.
You already paid for the traffic. StorePilot is the part that finds the leak, tests the fix the honest way, and proves whether it earned you more money per visitor. That is the whole job.
Questions merchants keep asking
Does Shopify have built-in A/B testing?
Not historically. Shopify shipped a native option called Rollouts in January 2026, which splits live traffic between theme versions server-side and shows you analytics. The catch is that it splits and reports, but it does not compute statistical significance, declare a winner, or judge results on revenue per visitor. Actual traffic-splitting and experiment analytics also require the Grow plan or higher. So you get the pipes, but you still have to decide what to test and whether the result is real.
How do I run an A/B test on Shopify without an app?
Two ways. You can duplicate your live theme, edit the draft, and serve one version per visitor using a sticky cookie so each shopper stays on their version, then track revenue per visitor yourself. Or you can use native Rollouts on the Grow plan or higher. Both are limited and neither judges the result for you: you still need to set a finish line in advance, run a full business cycle, and read revenue per visitor with a confidence interval before you trust any winner.
What is the difference between A/B testing and split testing?
For most merchants they mean the same thing: showing two versions to live traffic at the same time and measuring which earns more. The only nuance is convention. "Split testing" sometimes implies a whole-page or split-URL test, where each version lives at a different URL. "A/B testing" usually implies changing one element on the same page (a headline, a button, a layout block). The discipline is identical either way: randomize, keep visitors sticky, decide on revenue per visitor, and do not stop early.
How much traffic do I need to A/B test on Shopify?
Enough to detect your target lift inside a realistic two-to-six-week window. The hard truth from the math: a store at a 3% conversion rate needs roughly 53,000 visitors per variant to detect a 10% relative lift at 95% confidence and 80% power, which most small stores cannot reach in season. Below about 10,000 sessions on the page you want to test, switch to apply-and-measure with a holdback rather than waiting forever. You change what you test and how you measure, not just how long.
How long should a Shopify A/B test run?
Until you hit the sample size or duration you set in advance, whichever comes first, and never under one full business cycle. That means at least two weeks, ideally two full weekly cycles, so weekend and weekday behavior both land in both versions. Never stop early because a version looks ahead. Peeking daily for two weeks can push your real false-positive rate from 5% to about 26% (Evan Miller). Set the finish line before you start, or use always-valid sequential math that allows honest monitoring.
What should I A/B test first?
Start where the money leaks, which on most stores is the product page and cart, and start with your highest-evidence problem. Strong first candidates: a sticky Add to Cart bar on mobile, a reassurance line (shipping, returns, guarantee) near the buy button, and a free-shipping threshold with a progress bar. These are structural changes you can run on any plan, they tend to move revenue meaningfully rather than by a fraction of a percent, and they work better on low traffic because a bigger expected effect needs less data to detect.
What is the best A/B testing app for Shopify?
There is no single best one; it depends on what you are testing and your plan. Intelligems is built for price and offer testing. Shoplift is strong for theme, template, and page tests with no flicker. Native Rollouts is a free, safe traffic splitter if you are on the Grow plan. Standalone tools like Convert add full statistics. Pick by use case: theme and layout, price, or checkout, knowing that checkout testing is effectively limited to Shopify Plus. Prices listed by these tools change, so verify them live.
Can I A/B test prices on Shopify?
Yes. Intelligems is built specifically for price and profit testing and works around Shopify's price-test limits using cart-transform functions. Judge the result on revenue per visitor, not conversion rate, because a lower price almost always lifts conversions while shrinking your margin, so the version that "converts better" can earn less. Shopify also requires that prices stay consistent within a shopper's session and that they are real, not bait-and-switch. Treat margin and average order value as guardrails, and decide on revenue per visitor.
Can I A/B test the Shopify checkout page?
Effectively only on Shopify Plus, through Checkout Extensibility (UI Extensions for the interface, Web Pixels for tracking, Functions for discount and shipping logic). Standard plans cannot modify the checkout, because checkout is shared across theme versions and Shopify has been retiring the old customization paths: checkout.liquid and additional scripts sunset on August 28, 2025, and Shopify Scripts reach end of life on June 30, 2026. Everything storefront-side (product page, collection, cart page, homepage) is testable on every plan, which is exactly why the smart wedge is the product page and cart.
What is statistical significance and why does it matter?
It is the discipline of ruling out luck before you believe a result. There are always two reasons version B beat version A: B is genuinely better, or B got lucky in the random split. Significance estimates how often chance alone would produce a gap this big if the two versions were truly identical. A p-value of 0.03 means a gap this large would appear only 3% of the time by chance if there were no real difference. It does not mean a 97% chance B wins. It matters because without it you are just promoting a guess.
What is revenue per visitor and why use it over conversion rate?
Revenue per visitor (RPV) is total revenue divided by sessions, and it equals conversion rate multiplied by average order value. It is the metric that pays your bills because it counts whether people buy and how much they spend. Conversion rate only counts whether they buy, so it can rise while you make less money. A "10% off" banner can lift conversions from 3.0% to 3.6% while average order value falls from $80 to $62, dropping RPV from $2.40 to $2.23. A conversion-rate tool calls that a win; an RPV tool correctly calls it a loss.
How do I write a good A/B test hypothesis?
Write it as a single, testable sentence: "If we change X, then revenue per visitor will improve, because evidence Z." For example: "If we add a sticky Add to Cart bar on mobile, then RPV will improve, because 65% of stores bury the buy button below the fold and shoppers cannot find it." Keep it to one change so you learn what actually worked, name revenue per visitor as the metric you will decide on, and write down the evidence so the test is grounded in a real reason, not a hunch.
What is the peeking problem?
Peeking is checking a running test repeatedly and stopping the moment a version looks ahead. It inflates false positives because early random swings look like real effects: with enough data, any test will randomly cross the significance line at some point, even when the two versions are identical. Peek daily for two weeks and your real false-positive rate can climb from 5% to about 26% (Evan Miller). The fix is to set your sample size or duration before you start, or use always-valid sequential statistics designed to let you monitor safely.
Can small Shopify stores (under 10,000 monthly visitors) run A/B tests?
Yes, by changing what you test and how you measure rather than waiting forever. Test bold, structural changes (a sticky mobile Add to Cart, a new product-page layout, reviews versus none), because a larger expected effect needs far less traffic to detect. Use apply-and-measure with a holdback: ship the change to most visitors, keep 10 to 20% on the old version as a living control, and compare. Lean on cross-store evidence for well-proven, reversible fixes. Accept "likely" confidence rather than "strong," and have a human approve before anything sticks.
What is the difference between Rollouts and third-party apps?
Rollouts is Shopify's native server-side splitter: it divides traffic between theme versions with no flicker and offers scheduled releases and automatic rollbacks, but it has no statistics engine, no winner call, and no concept of revenue per visitor. Third-party apps add what Rollouts lacks: significance and confidence intervals, revenue-per-visitor verdicts, price and checkout testing, audience segmentation, and low-traffic methods. A sensible setup uses Rollouts as the safe traffic splitter and lets a smarter tool decide what to test and whether the result actually earned more money.
How do I know if my result is real or just noise?
A result is real when it survives a short checklist, not when the dashboard turns green. Confirm the split came out as designed (a Sample Ratio Mismatch check passed), that the test ran at least one full business cycle, and that no sale or promo contaminated the window. Then check that the 95% confidence interval on revenue per visitor excludes zero, that the win holds across devices rather than reversing on mobile, and that it is not driven by one whale order or an early novelty spike. If it clears all of those, translate the lift into a dollar range and ship.